

Raiden Mark I
I wrote an introduction to the Raiden project awhile back, but it’s been too long since I’ve done an update, and a lot has happened in the meantime. I’ve been keeping a fairly detailed log (which may be part of the reason I’ve neglected to post updates) but in terms of progress there’s a lot of log entries without a lot of results. So in this post I’ll focus on the highlights and talk a little about how the progress so far fits into the overall project. Along the way I’ll mention some of the key objectives of the project and outline the major stages as some of this has come into focus since my original post. Around the beginning of this month I started to put together the hardware that will make-up what I’m referring to as Raiden Mark I. I chose this configuration for a number of reasons but the overall goal is to build a supercomputing cluster (albeit a small one) which resembles the typical Linux supercomputer. This will be used to establish a baseline for performance, power consumption, cost, etc. 
Original Raiden Mark I Hardware Configuration
Qty Device Processor Clock RAM Storage
8 HP DL360 G5 Dual-core Xeon 3Ghz 8GB 30GB
1
Cisco Catalyst 3500 XL
N/A
N/A
N/A
N/A
The other rationale for this configuration is that it’s what I have on-hand. The most obvious bottleneck is the fast-ethernet switch, which could be cheaply replaced with a gigabit one however I saw no point in buying more hardware until I could at least get the system operational with what I already have. The one downside to this is that I had to figure out how to partition the switch to isolate the cluster traffic, but after digging through some dusty PDF’s that was all set. I found some very nice IBM tutorials on building simple Linux clusters which in turn led me to Rocks Linux distribution. Rocks takes care of a lot of the grunt work common to most Linux-based clusters and while it took a little experimentation to cover some gaps in the documentation, the end result was a much faster and more consistent setup than I could have done by hand. I was hoping Rocks would get the system to a point where I could run LINPACK and start measuring the systems performance (starting with just one front-end and one compute node) but some of the dependencies were not where I expected to find them, and after an evening of attempting to build them from source (resulting in my first parallel segfaults), I set the system aside for awhile to work on other projects. When I had time to come back to it, I decided to start over and learn how to write my own parallel programs to test the system. Once I knew more about building and running things on the cluster, I’d give LINPACK another try. This was more successful. In fact, in just a couple hours I was writing my first MPI programs and watching them run across the cluster. With this success under my belt I was ready to take a swing at adding more nodes to the system. I had picked up a few more bits of information since the last time I installed Rocks and this time around figured out I didn’t even need the installation CDs to add more processing nodes. All I had to do was re-arrange the boot order a little and blow-away any existing bootable installation on the storage array and like magic the new nodes booted from the network! This moved things along double-quick until everything went dark. Literally, the lights went out. Around the time I booted the fifth node in the cluster a circuit breaker tripped and everything stopped. On one hand this shouldn’t have been a surprise, I had the cluster on the same circuit as a bunch of other equipment in the lab and clearly 8 servers would be capable of overwhelming a 15 amp circuit. On the other hand I was kind of surprised that the system would pull that much power when it was for the most part idling, but in any event it was clear that the cluster needed its own circuit. So I pulled a heavy-duty extension over to an an outlet on its own breaker and tried again. Things went well, in fact faster than the first time. I wasn’t sure what state things were in due to the power interruption so I rebuilt all the compute nodes from scratch. I was nearing the end when everything got quiet again, another power fault but this time it was only the cluster that went dark. This time it was one of the power strips I was using to feed the cluster. Again this probably could have been predicted but at this point I’d had my fill and decided to call it a night. However as I ascended the stairs I heard the roar of all eight nodes firing up simultaneously. Apparently the breaker that tripped was the kind that resets itself and I knew that this would become a loop of reset-trip-reset if I didn’t interrupt it manual so I ran back down to the lab and manually switched-off all but the front-end node. Later that night I ran some numbers and realized that the amount of work involved in getting enough power to the cluster to run it (with some extra headroom for safety) would probably outweigh any benefits of having eight nodes in the system. There’s no specific reason I wanted to start with eight nodes other than that is what I have and it seemed more interesting than something smaller. However, in light of the power distribution problems (as well as other associated costs), I’ve decided to scale the system back to five nodes (one front-end and four compute). This will let me run the compute nodes on a single 15 amp circuit and move the front-end node (which is harder to replace if I corrupt it) to a separate circuit. This also reduces the hardware cost for the next phase of the experiment, “Mark II” (more on that in a future post). For now it’s back to the lab to once again setup compute nodes (hopefully without another blackout). After a little rewiring the front-end node came up without issue, so I started bringing up the four selected compute nodes slowly, one-by-one. 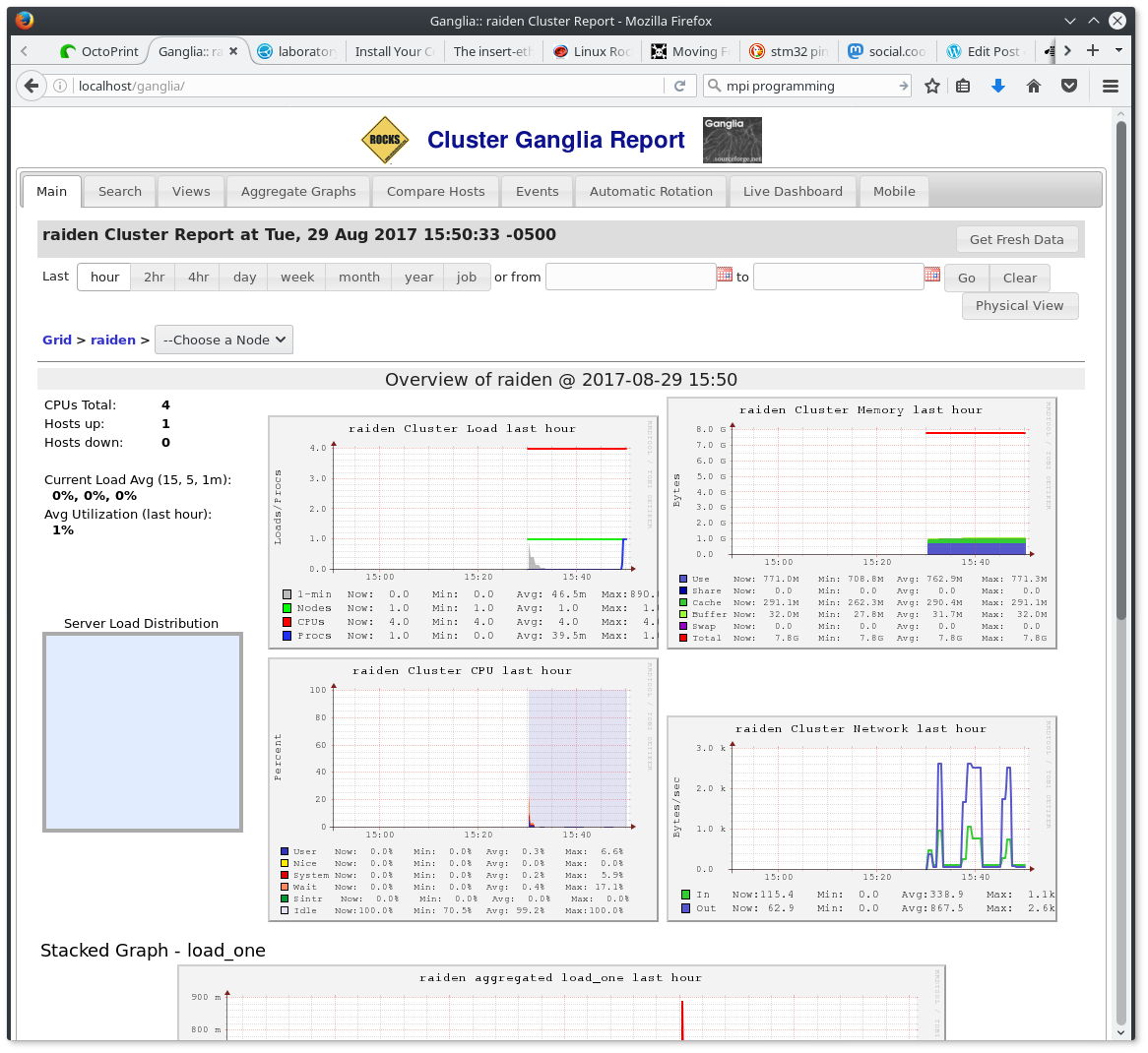 Unfortunately I ran into trouble with the first compute node. It wasn’t showing up in Ganglia (the cluster monitoring system) and when I attached a monitor there was nothing but a black screen. Looks like round three deleting and re-installing the compute nodes. But then, after I cold-booted the node it started-up and launched into setup. After about 15 minutes it rebooted and showed up in Ganglia!
Unfortunately I ran into trouble with the first compute node. It wasn’t showing up in Ganglia (the cluster monitoring system) and when I attached a monitor there was nothing but a black screen. Looks like round three deleting and re-installing the compute nodes. But then, after I cold-booted the node it started-up and launched into setup. After about 15 minutes it rebooted and showed up in Ganglia! 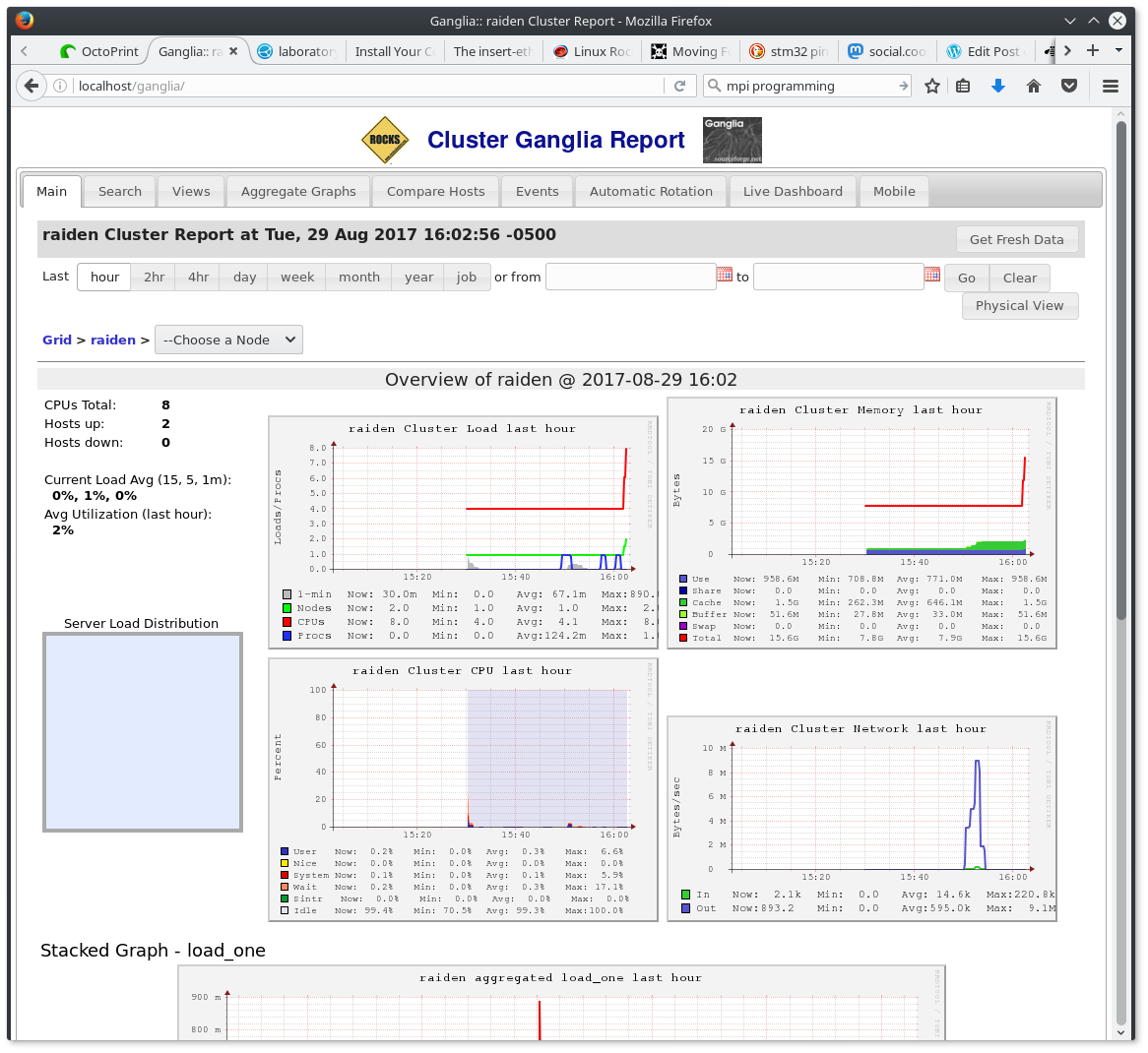 The same process repeated for each node. I’m not sure if setup was just incomplete on the compute nodes when the power went out, or if something else toasted them but this “self-healing” behavior is pretty handy and another great feature of the Rocks distribution. Within an hour, the supercomputer should be fully operational… So close! Another power fault. This time I can only suspect the power strip I’m using for the four servers. I would assume it can handle 15A, but looking at it I can’t see any indication as to it’s capacity. After a few minutes it reset itself and all four servers roared to life.
The same process repeated for each node. I’m not sure if setup was just incomplete on the compute nodes when the power went out, or if something else toasted them but this “self-healing” behavior is pretty handy and another great feature of the Rocks distribution. Within an hour, the supercomputer should be fully operational… So close! Another power fault. This time I can only suspect the power strip I’m using for the four servers. I would assume it can handle 15A, but looking at it I can’t see any indication as to it’s capacity. After a few minutes it reset itself and all four servers roared to life.